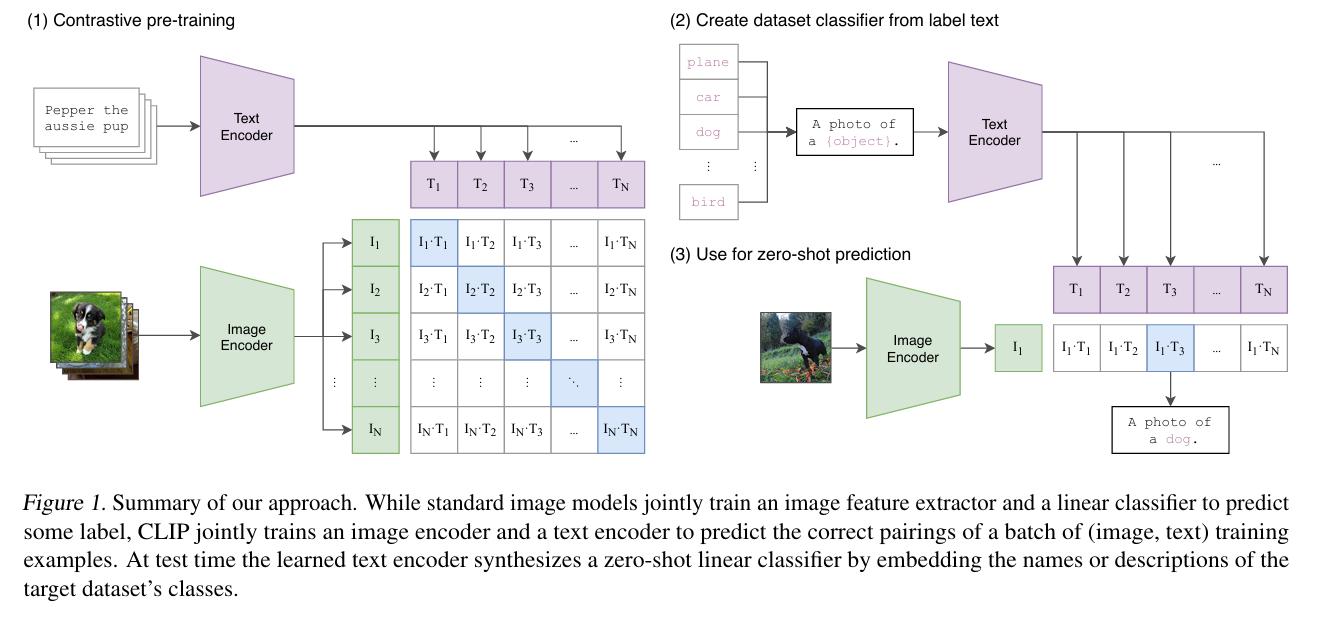
CLIP:Contrastive Language-Image Pre-Training
CLIP 和 MAE 是 ViT 模型的两大预训练方式,MAE 专为 ViT 设计,而 CLIP 主要是打通图像和文本的语义连接。
CLIP 原理
CLIP 概述:
- 训练内容:CLIP 训练一个 Image Encoder 与一个 Text Encoder
- 训练目标:如果图像与文本是匹配的,则将它们在特征空间中拉近,如果是不匹配的,则将它们推远
CLIP 训练过程(Contrastive Pre-Training) :
- 输入:单个批次输入 $N$ 个【图像-文本】对
- 编码:$N$ 张图片被送入 Image Encoder,生成 $N$ 个图像特征向量。同时 $N$ 段文本被送入 Text Encoder,生成 $N$ 个文本特征向量
- 对比学习:模型生成一个 $N \times N$ 的相似度矩阵,其中 $(I_i, T_j)$ 表示第 $i$ 张图像与第 $j$ 段文本的相似度
- 优化训练:最大化对角相似度,最小化非对角相似度
应用/推理(零样本预测 Zero-shot Prediction) :
- 创建 Prompt:不能只用
dog 之类的单个词,而是要使用A photo of a {object} 之类的句子。选择 $M$ 个目标单词,构成 $M$ 个句子,并将句子传入文本编码器。 - 输入图片:将要分类的图片输入已经训练好的图像编码器,得到特征向量 $I_1$。计算其与前一步文本特征向量相似度。得分最高的文本对应的类别即为最终预测结果。