论文阅读-Benchmarking Optimizers for Large Language Model Pretraining
Original Paper: [2509.01440] Benchmarking Optimizers for Large Language Model Pretraining
Introduction
Chinchilla Scaling Law: The optimal amount of training data for a given model size that yields the best performance under a fixed computational budget. To be more specific, we need around 20 text tokens per parameter (see 2203.15556)
Overview: We discuss the algorithms according to their logical grouping:
- Adam-like methods:
AdamW,ADOPT,AdEMAMix - Sign-based methods:
Lion,Signum - Approximate second-order optimizers:
Muon,SOAP,Sophia - Learning rate/ scheduler-free learning algorithms:
Schedule-Free AdamW,Prodigy - MARS methods:
MARS
ADOPT: Remove the current gradient $g_t$ from the second moment estimate $v_t$ and alter the order of the momentum update $m_t$ and normalization.

AdEMAMix (Dual EMA) : This work argues that using a single EMA to accumulate past gradients in the first moment estimate $m$ can be suboptimal, as it cannot simultaneously prioritize both immediate past and older gradients.

Lion: Lion is a sign-based method, which determines the update direction by taking the sign of an interpolation between the previous momentum and the current gradient.

Signum: This method differs from Lion in the interpolation term between the EMA of momentum and the current gradient.

Muon and D-Muon: In Muon’s original code, weight decay does not apply to the matrix parameters in MuonNon1D. This weight decay issue is addressd in [2502.16982] Muon is Scalable for LLM Training, in which the authors present a scheme for sharing the learning rate and weight decay between the matrix and non-matrix parameters of the model.


SOAP: SOAP improves Shampoo and reduces the computational overhead by optimizing only two-dimensional layers while running AdamW for 1D layers.

Sophia:

Schedule-Free AdamW: The idea of Shcedule-Free AdamW is to eliminate learning rate schedulers by replacing them with iterate averaging.

Prodigy: Prodigy removes the need for hand-tuned learning rates through an intrinsic, adaptive step-size scheme.

MARS: MARS incorporates modern adaptive and approximate second-order methods with a variance reduction update style.

Results at Small Scale: 124M Models
Notation: Hereafter, “$A \times B$ tokens” indicates the batch size is $A$, and each batch contains $B$ tokens.
Results with Small and Large Batches and Stability across Training Horizons

Takeaway (Batch Size)
AdEMAMix consistently achieves state-of-the-art performance and robust scaling with training duration.- Sign-based methods (
Signum,Lion) andMARS greatly benefit from the increased batch size.Sophia diverges in small-batch setting, when trained beyond the Chinchilla optimal horizon, even with sufficiently small learning rate;SOAP show a consistent performance in both settings.Takeaway (Stability) : Once optimizers are properly re-tuned for the maximal length of training considered, doubling of number of iterations does not affect the ranking of methods.
Increasing the Batch Size Further:
Takeaway: Many methods, especially
MARS,Prodigy, andsign-based ones, can outperformAdamW while trained on a sufficiently large batches.
Weight Decay Ablation:
Here the baseline AdamW uses a weight decay of $\lambda = 0.1$.

Takeaway:
- The use of weight decay (particularly a large weight decay term 0.5 and above), can significantly impact the final loss and optimizer behavior.
- The setting of weight decay to be $0$ is suboptimal.
- For extended training horizons, non-zero weight of $0.1$ proves to be a robust option.
Learning Rate Sensitivity:
Takeaway:
- For most optimizer, the learning rate $\gamma_{\max}$ selected near the Chinchilla optimal horizon transfers smoothly to $8 \times$longer run.
- Sign-based methods and
Sophia diverge with $\gamma_{\max} = 2e^{-3}$.MARS demonstrates a very consistent performance across $\gamma$ sweep.
Warmup Ablation:
Takeaway: We reveal that the warmup duration is optimizer-dependent and should be tuned: for
SF-AdamW,Sophia, andSignum, longer warmup results in improved final performance.
Warmup Types of WSD(Warmup-Stable-Decay), cosine, and linear **$\gamma$** -scheduler:

Takeaway: A choice of the learning rate scheduler is also optimizer-related
- For most methods, the cosine scheduler dominates.
- Linear scheduler outperforms or matches cosine and WSD for sign-based methods,
SOAP andMARS.- WSD appears to be the best option for
Muon
Results at Medium Scale: 210M Models
Results

Takeaway:
- We do not observe a much of a change in ranking of optimizers for 210M model, compared to benchmarking on 124M.
- We replicated almost identical hyperparameters for all optimizers, except for the learning rate for sign-based methods (which is more sensitive to the learning rate while scaling the model size)
Decay the learning rate sufficiently
Takeaway: Decaying the learning rate further than $10\%$ of the maximal significantly improves the results. However, for different schedulers, the best final learning rate is different.
Results at Large Scale: 583M and 720M Parameters
Results

Takeaway:
- At larger scale of model and batch size,
AdEMAMix andMARS dominate.- Despite training with large batches,
Signum andLion scale poorly.D-Muon is consistent across all our benchmarking setups.
Wall-clock time comparison
Takeaway: Most optimizers exhibit similar wall-time performance, with sign-based methods being slightly faster.
SOAP is the main exception.
Extension to MoEs
MoE:
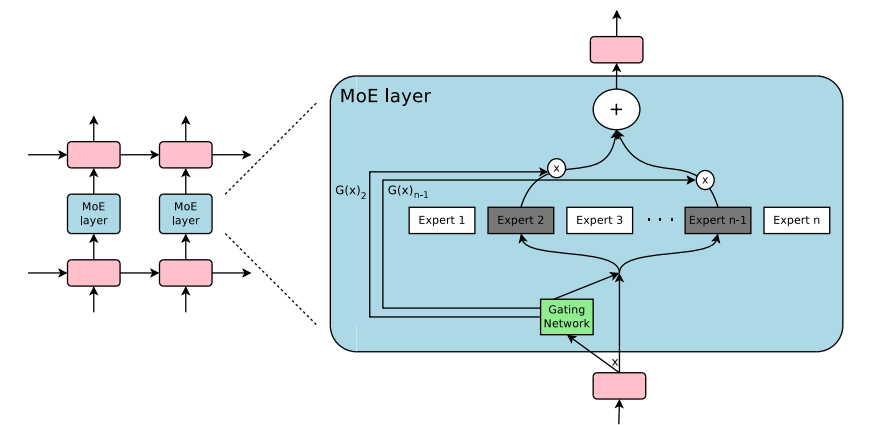
Results:

Takeaway: Benchmarking results obtained for dense models transfer to corresponding MoEs.